The Data Engineering Testing Series
The Test Pyramid, Data Engineering, and You!

Writing your first test can be a daunting moment. Every test comes with a cost and some more than others. You will find yourself asking questions such as:
- What do I test?
- Do I test the whole system?
- Do I test every function?
- How many tests do I need?
- How many failure scenarios am I satisfied with? If any?
Unfortunately, I can’t explicitly tell you the answer to what is right or wrong for your particular scenario, but hopefully, this post can help you out. I’m going to walk you through the process of creating tests for a simple data pipeline in Julia. Why Julia you ask? Because it’s cool.
The rest of the series continues as below:
Part 1: Why Great Data Engineering Needs Automated Testing
Part 2: The Keys To Unlock TDD For Data Engineering
Part 3: The Test Pyramid and Data Engineering (with Julia)
Part 4: What is Data Quality Really?
The Scenario
In our fictional scenario, we work for a cryptocurrency platform that helps investors track their trades. As part of our platform we’ve hired an external vendor to deliver the following timestamped Arrow DataFrame to us at some regular interval:
20200114_151100_new_investors.arrowDataFrame(
names = String[],
countries = String[],
net_worth = Int64[],
holdings = Float64[],
y = Int64[],
z = Int64[],
id = String[]
)
The boss upstairs is chomping at the bit to know how many people from each country are in this DataFrame so they can focus their marketing efforts. They want to keep track of how the number of new investors per country changes over time.
Our data is luckily being delivered in a nice structured format (being Arrow), the timestamp is in UTC, and it should only contain new investors, thus we should not have to worry about deduplication, time zone issues, or deserialization.
Choosing your test scope
Before we jump in, let’s gather an understanding of the theory behind test pyramids. Simply put, there are several levels of testing, and as you move up the levels, the tests become increasingly flaky and expensive. Take building a table for example, the legs, the bolts, the brackets, and the tabletop are the individual parts, and you then put them together, eventually to form a whole system.
To test this table, first, you can look at all the parts and make sure they are structurally sound. This would be a unit test, it’s quick and easy to do. You can then start putting the parts together, forming a larger system, and testing that they also work together. Perhaps you pull on the legs to make sure they’re attached to the bolt and the bracket. An integration test, which is a slightly more labour intensive exercise. Finally, you put the tabletop on and make sure you can stand on top of the entire table. The final end-to-end test, and most expensive.
The basic philosophy behind test pyramids is that unit tests are superior to end-to-end tests as they are much faster, have obvious failure points, and are reliable. Thus you should invest in having lots of unit tests, a few integration tests, and even fewer end-to-end tests. In our table scenario, if we’re confident that all the parts are structurally sound and they fit well together, we probably don’t need to stand on it much. Likewise, if our end to end test fails, we don’t know whether it’s the bolts, or the bracket, or any other piece that’s the problem until closer inspection.
Pivoting back to data testing, we should look at the levels we can test it in a slightly different way to software. This is because instead of three levels of tests (unit, integration, and end-to-end) you usually have five. These levels are highlighted by layers of the dotted lines in the diagram below.
- Full system, including client
- Pipeline, including service
- Multiple jobs
- Single job
- Unit/component
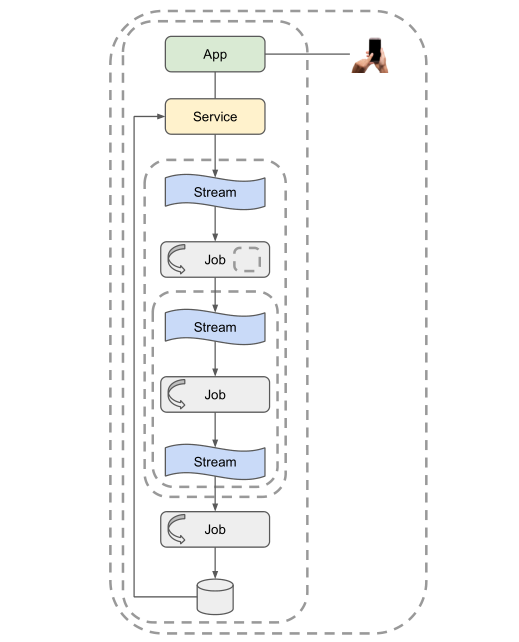
One of my favourite resources on this subject is Lars Albertsson (it’s also his diagram above). He suggests that with data it’s only worthwhile testing at the job to pipeline level. His argument being that unit tests are too volatile because ‘the data’ in data pipelines is often rapidly changing. This level of testing works because each job in a data pipeline is essentially a black-box function, free from external factors, so it shares many of the same advantages of unit testing.
However, let us consider our scenario again, this is where I prefer to follow the advice of Kent Beck, one of the leaders in TDD thinking.
I get paid for code that works, not for tests, so my philosophy is to test as little as possible to reach a given level of confidence (I suspect this level of confidence is high compared to industry standards, but that could just be hubris). If I don’t typically make a kind of mistake (like setting the wrong variables in a constructor), I don’t test for it. I do tend to make sense of test errors, so I’m extra careful when I have logic with complicated conditionals. When coding on a team, I modify my strategy to carefully test code that we, collectively, tend to get wrong. — Kent Beck on Stack Overflow
The scope that’s right for me
Immediately upon looking at our task we can see we got three tasks in our pipeline and that it should only consist of one job:
- Read in an Arrow file as a DataFrame (unit test)
- Parse the timestamp and perform the aggregation (unit test)
- Append the new data to an existing DataFrame (unit test)
In a real-life scenario, where the disk could be an object store (S3, ADLS Gen 2, Cloud Storage), our system would also have to address the following issues:
- How do we keep track of what Arrow files we have already consumed? (unit/integration test)
- How do we manage different versions of our country count history DataFrame? (unit/integration test)
- What are we going to use for compute? (integration-test)
- How are we going to trigger (orchestrate) the compute to do our job? (system/integration-test)
- How are we going to ensure the integrity of the data we’re consuming? (unit test)
- What would we do if the data did not arrive when expected? (integration-test)
- How do we recognize and recover from failures? (unit/integration test)
- How do we deliver the data to the dashboard? (integration-test)
- How do we keep our data safe? (system/integration-test)
We don’t have the time to address all these issues, so I’m going to assume that our job will be running inside a container that is triggered manually, and for our MVP, generating the aggregated dataset is enough. I will use storage inside the container as a proxy for the object-store.
This dramatically reduces the scope of what I think I need to test. Remember, we get paid for code that works, producing value at the end of the day is all that matters. With this in mind, I’m going to go with five tests to get started quickly:
- Unit test to aggregate the data to perform the country counts
- Unit test to parse the DateTime from the filename
- Unit test to add that DateTime as a new column to the aggregated dataset
- Integration test to make sure that all three units work together (job level)
- Manual test to make sure the Julia container runs to completion when triggered (system level)
Notice how I am not going to unit test whether I am reading and writing the data correctly. I also skipped unit testing whether the DataFrame append command works. I am going to assume that the libraries that are doing these functions for me already work. Additionally, I will get test coverage of this with the integration test. I opted for a manual test of the container because Medium articles don’t come with CI/CD pipelines.
Setting up the project
The first thing we will have to do is set up the repository structure. In Julia, you must create a folder with the intended name of the package, navigate to that folder, then use the REPL to activate the environment. You must then create the following two scripts to enable the package and tests.
<package_name>/src/<package_name>.jl<package_name>/test/runtests.jl
Julia requires these files with these specific names for it to work. At the end we have the following directory structure:
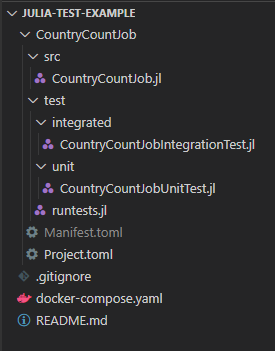
To help split up the tests into their own scripts I am employing the use of the Jive package. This will allow me in the future to add extra scripts in my test folder that can be ignored when running tests. It also makes the runtests.jl file quite succinct.
The tests
Since this is the first run I will only write tests for the happy path, that is, the form of what I expect the data to be. So lets start by with the unit tests:
You will notice a few things here:
- Each of the unit tests we identified corresponds to functions in the application.
- The tests are extremely simple and exclude unnecessary columns.
- Creating DataFrames in Julia is quite a bit more succinct than in other languages. Simply declare the column name as the argument.
Now onto the integration test, which is at the job level. Here, we produce files and save them to disk, testing not only that we read the data correctly, but that we write the right data back. I also threw in a few dummy columns to the input to make sure that they didn’t impact the desired result.
Here I write out the input and the expected output to disk (lines 23–24), call my main function (line 28), make my assertion (line 38), then clean up the results. I couldn’t find a neat way in Julia to implement the usual test setup and teardown functions that are available in suites such as pytest, so if the test failed for whatever reason, the files remain on disk (if you know how to do this please leave a comment below).
The Country Count Application
As we have planned out our tests, we now want to match our functions with the functionality we are seeking to achieve.
This “job” script contains six different functions. Notice how I could have put all this code inside the main function easily enough, but to test the individual pieces we have to split them up into their own functions.
Finishing Touches
Now let’s create our final manual test, which will be just running the test suite to completion. This will test whether we’ve set up our Julia project correctly.
To run simply navigate to the CountryCountJob folder in your console then run docker-compose run julia-data-testing. Docker will take care of most of the heavy lifting, and we will be left with the following output.
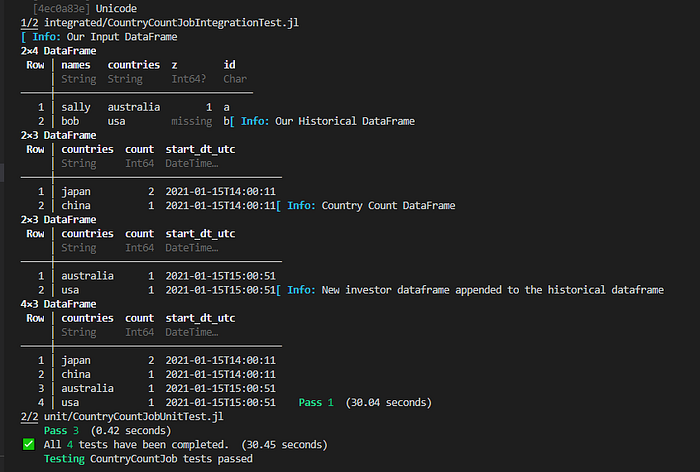
The devil of structural coupling
For those savvy software architectural experts out there, you would have noticed that we are coupling the structure of our program to our tests. This is generally considered to be an anti-pattern in software development, as now you need to change your tests when you change your program, which of course contributes to test fragility.
However, keep in mind that we are working with data pipelines, and while it shares similarities with software projects, it’s not necessarily the same thing. Remember at the job level, we are essentially working with singular black-box functions, thus we are not dealing with an intense amount of coupling. If it is a deal-breaker for you though, you may forgo the unit tests and just have an integration test (Lars’s suggested pattern).
The main contributor to test fragility in data is usually when jobs share the same changing data source. This is where we bump into one of the main sticking points of this approach… when the real data changes, how do we make the right tests break? That will be next time.
Thanks for taking the time to get this far and please feel free to leave any comments below or reach out to me on LinkedIn.